You're Not Above the Loop. You're Building It.
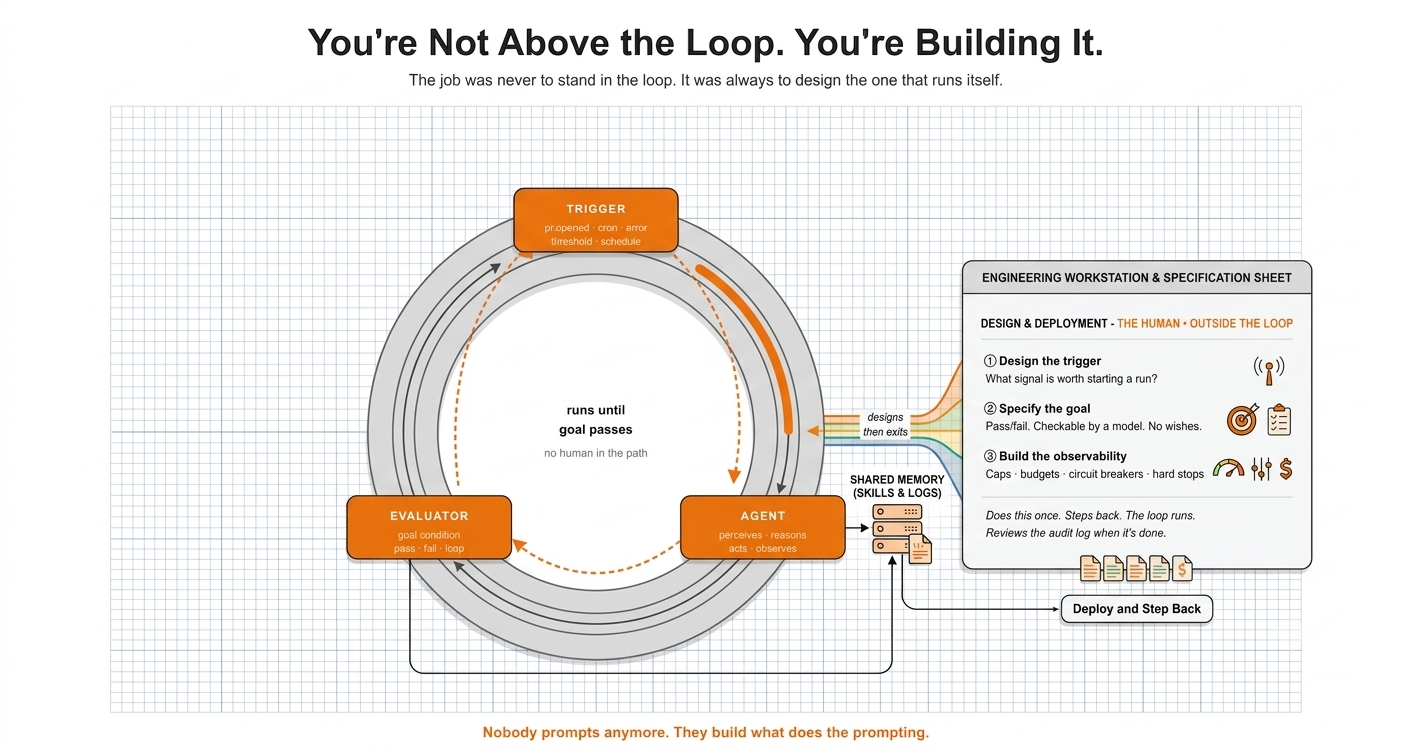
A PR opens Monday night. By Wednesday morning it has been built, tested against a spec, and merged. Nobody typed a prompt into a chat window to make that happen. A harness picked up the trigger, ran the agent until an evaluator confirmed the goal, and logged the result. The first human to look at any of it was the reviewer checking the log two days later.
Nobody got better at prompting here. They stopped prompting. They built the thing that prompts itself.
That is loop engineering, and it moves the human further out than I thought.
The Framing That Is Already Incomplete
In The Human Was Always the Next Ceiling, I argued for human-above-the-loop. Define the goal, set the boundaries, let the agent run, check the log after. Get the human out of the middle and onto the edges.
It already looks incomplete.
It still assumes the loop already exists and your only decision is where to stand around it. That the interesting work happens inside the agent, and your job is just figuring out your relationship to it.
That is backwards. The loop is not something you find a position relative to. The loop is the thing you build.
Human-above-the-loop asked where you stand. Loop engineering asks what you build.
A Loop Is Just Two Things
A trigger, and a goal you can check.
The trigger starts the work without you. A PR opens. An error crosses a threshold. A cron fires. The agent does not wait for you to notice something is happening.
The goal is what “done” means, stated precisely enough that a model can check it. Not “make progress.” Tests pass. Coverage holds. The diff matches the spec. If you cannot write the goal as a pass-or-fail condition, you do not have a loop yet. You have a request.
Most teams building “agents” right now are still doing prompt-response with extra memory bolted on. Ask, get an answer, wait for the next ask. That is a chat interface with tool access, not a loop.
The difference matters because the failures are different. A bad prompt gives you a bad answer once. A bad loop runs all night on the wrong goal and burns money doing it.
You are not writing prompts anymore. You are writing what generates them.
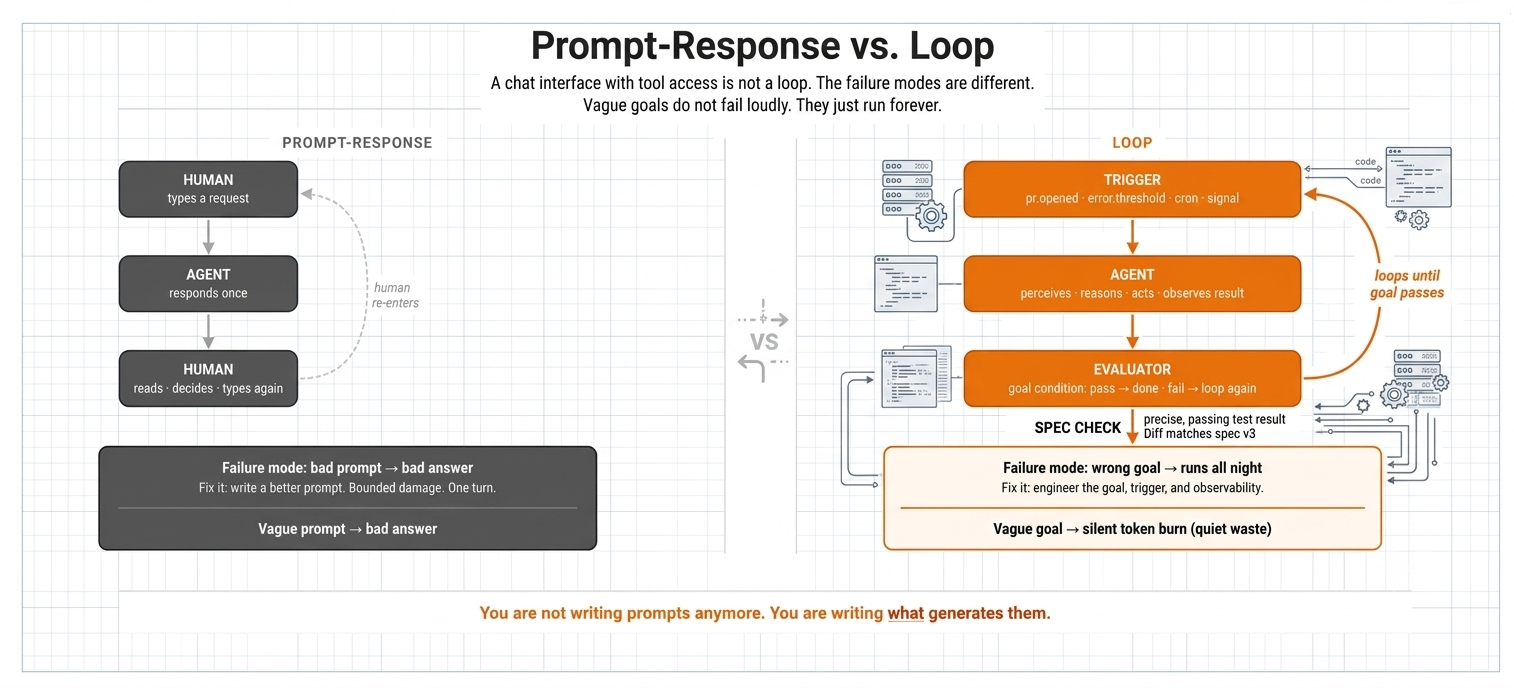
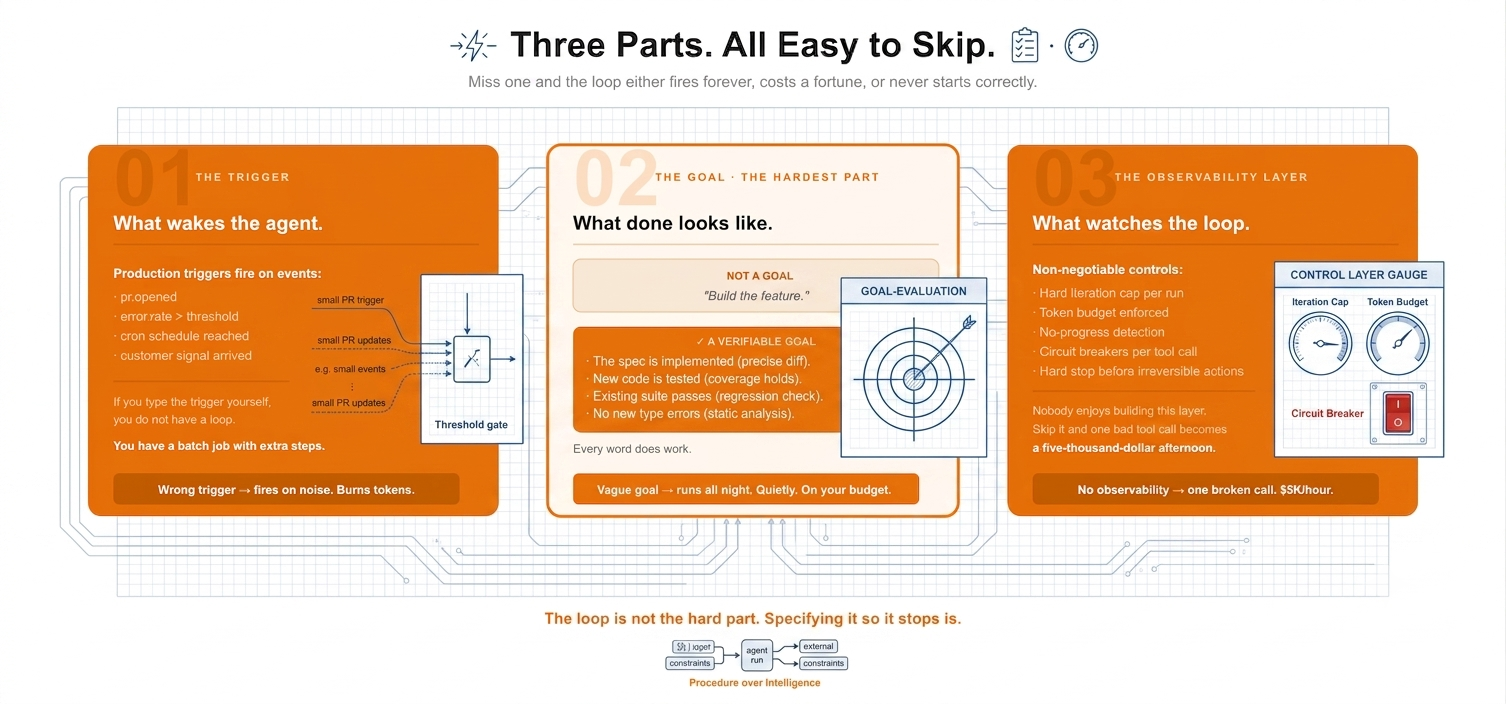
Three Parts, All Easy to Skip
A trigger. A goal. And something watching the loop while it runs.
The trigger decides what is worth waking the agent for. Get this wrong and the loop fires on noise, all day, for nothing.
The goal is the hard one. “Build the feature” is not a goal, it is a wish. “The spec is implemented, new code is tested, the existing suite still passes, no new type errors” is a goal, because a model can check every clause of it. Vague goals do not fail loudly. They just run forever, quietly, on your token budget. This is the same discipline I wrote about in Procedure Over Intelligence: encoded constraints, not real-time supervision, are how reliable agents get built. Loop engineering extends that insight from a single agent run to a system that runs itself.
The third part is the one nobody enjoys building: iteration caps, token budgets, no-progress detection, a hard stop before anything irreversible. I wrote about this layer in Building the Control Layer. Skip it and one bad tool call turns into a five-thousand-dollar afternoon. This has actually happened. More than once.
The loop is not the hard part. Specifying it so it stops is.
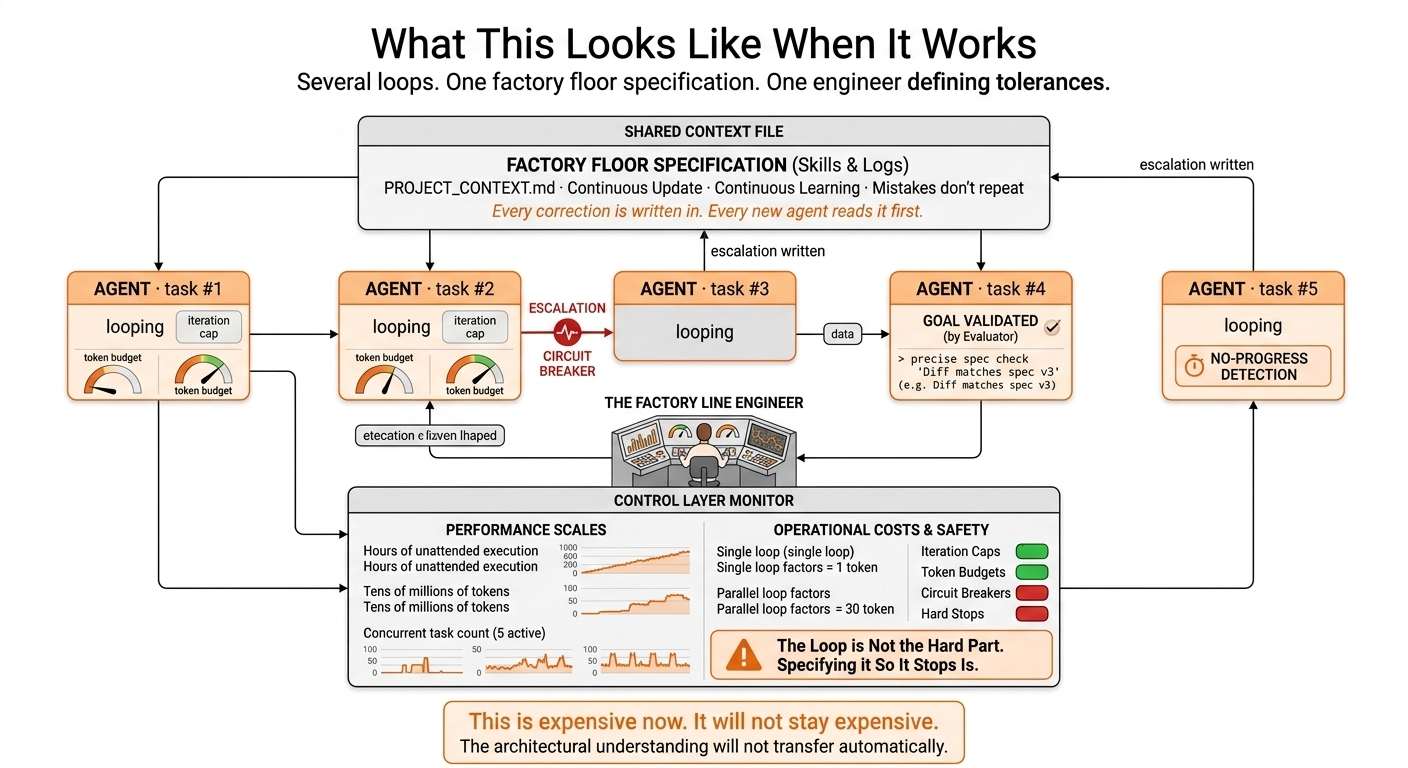
What This Looks Like When It Works
The pattern I keep seeing: several agents running in parallel, each on its own numbered task, pinging a human only when something genuinely needs a call they cannot make. And underneath all of it, one shared file that every new agent session reads first.
That file is the real trick. Every time an agent gets corrected, the correction gets written down. The next agent reads it before it makes the same mistake. It is the same job Skills do in a harness, just running continuously instead of being loaded once.
The scale this reaches is not small. Hours of unattended execution. Tens of millions of tokens. None of that is a long chat session. That is a production line with one person watching the gauges.
It is not cheap yet. A single agent burns roughly four times the tokens of a normal chat turn. Run several in parallel and that multiplies fast. RAG looked expensive in 2023 too, right up until it did not.
This is expensive now. It will not stay expensive, and the gap between knowing the architecture and not knowing it will not close on its own.
The Job, Restated
In Three People. Ten Agents. Zero Sprints., three people with ten agents shipped what a twelve-person team shipped in two weeks. That was about fleet management.
This is what running that fleet actually means day to day. Not directing each agent through its task. Designing the loop it runs in, writing a goal precise enough for a model to grade, and building the memory that keeps the same mistake from happening twice.
It is still engineering. Maybe more of it than before. You used to need good judgment to write good code. Now you need it to define what “correct” even means, before anything runs.
The factory floor analogy from The Session Was Always the Ceiling still holds. But the human’s role has clarified. You are not the floor supervisor signing off on each part coming off the line. You are the one who built the line, set the tolerances, and decided what a defect looks like. Then you stepped back.
Nobody prompts anymore. They build what does the prompting.
Resources & Next Steps
- Agentic Loops: From ReAct to Loop Engineering (Data Science Dojo). The clearest current breakdown of how the term came together.
- Loop Engineering thread by Peter Steinberger (@steipete). The post that started this.
- Related post: The Human Was Always the Next Ceiling.
- Related post: Building the Control Layer
- Related post: Procedure Over Intelligence: Building Reliable AI Systems
- Related post: The Session Was Always the Ceiling.
- Related post: Three People. Ten Agents. Zero Sprints.