Building the Control Layer: How Agent Harnesses Make AI Reliable
The agent worked. The system around it didn’t exist.
You’ve probably done this: pointed an agent at a codebase and watched it scaffold a feature in fifteen minutes. Impressive. Then you pointed the same agent at the same codebase the next morning. It forgot every convention it followed yesterday. It rewrote a module it already built. It hallucinated an API endpoint that no longer exists.
The model didn’t get dumber overnight. The model was never the system. It was always a component inside a system nobody designed.
The infrastructure around the model determines whether agents work. The model just generates tokens.
The OS Nobody Built
When teams hit reliability problems with agents, the instinct is to upgrade the model. Bigger context window. Better reasoning. More parameters. This rarely fixes anything, because the model was never the problem.
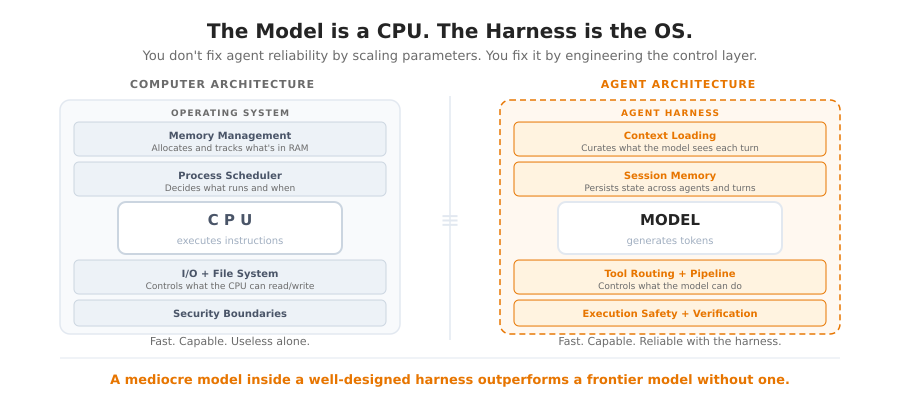
Think of the model as a CPU. Fast. Capable. Useless without an operating system managing its memory, scheduling what it sees, enforcing what it can touch, and deciding what happens when something fails. Without that layer, the CPU just runs hot and crashes.
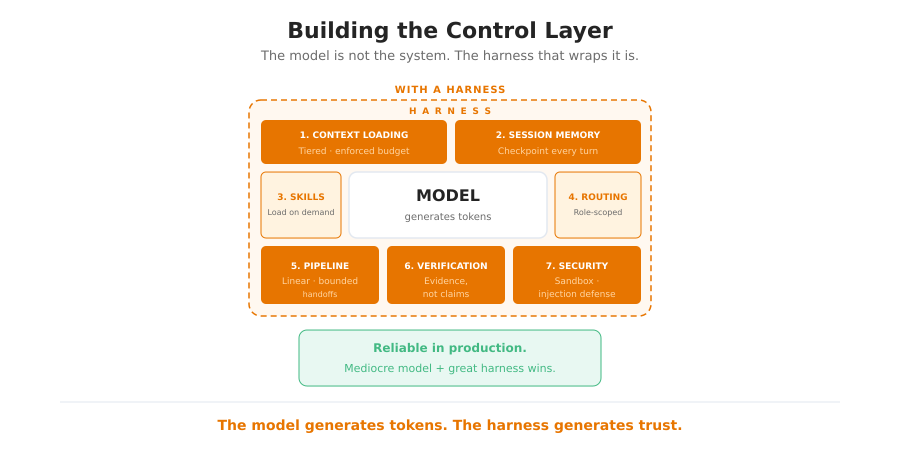
An agentic harness is that operating system. It manages what the model sees at each step, what tools it can call, how errors propagate, and how work persists between sessions. The harness assumes responsibility for everything except the actual generation.
The pattern I keep seeing: rewriting the control layer yields larger reliability gains than swapping models. A mediocre model inside a well-designed harness outperforms a frontier model running without one every time. The harness is the differentiator. Not the model.
So what goes into it? I’ve been building and iterating on a multi-agent orchestration system for GitHub Copilot in VS Code and have converged on seven ingredients. Some are table stakes for any single agent. Others only become visible when you’re coordinating twelve agents across a pipeline.
You don’t fix agent reliability by scaling parameters. You fix it by engineering the control layer.
What the Model Sees Determines What It Does
The first question any harness must answer: what does the model see on each turn?
Load too little and the agent loses context. Load too much and the context window fills with domain knowledge before any task-specific reasoning begins. When twelve agents share a project, the data engineer needs pipeline patterns. The security reviewer needs OWASP checklists. Neither needs both. But naive systems load everything into every agent every time.
The fix is simple in principle and easy to underinvest in: tiered loading.
.copilot/context/
PROJECT_CONTEXT.md ← Always loaded (< 200 lines)
ORIENTATION.md ← Always loaded: 5-min quick-start
ARCHITECTURE.md ← Loaded for architecture tasks
CODEBASE_PATTERNS.md ← Loaded for coding tasks
DECISIONS.md ← Loaded only when referenced
The always-loaded layer has a hard budget: under 200 lines, no exceptions. Not a suggestion. A constraint. Because it loads into every task, a bloated always-loaded layer degrades reasoning quality across everything downstream. The constraint forces a decision that most teams avoid: if everything is critical, nothing is.
Domain-specific context loads only when the task matches. Historical decisions load only when explicitly cited.

The Meta-Harness research from Stanford (March 2026) put numbers on this. An automated system that optimized what the model sees at each step, without changing the model itself, achieved a 7.7-point accuracy gain over a state-of-the-art baseline while reducing token costs by 4x. The model weights did not change. Only the context did. That is where the gains are.
Context capacity is not the constraint. Context curation is.
Agents Forget. Systems Remember.
Single-agent systems have a memory problem. Between sessions, context resets. The agent starts fresh every morning with no idea what it built yesterday.
Multi-agent systems have a harder problem. Not just forgetting across time, but forgetting across agents. One agent finishes its work. The next one starts blind. No shared state. No handoff. The work has to be reconstructed from scratch.
The fix is a checkpoint file. Written at the end of every agent’s turn. Read at the start of the next.
# Session State
Last Agent: senior-developer
Status: paused
## Completed
1. architect: Spec approved, saved to .copilot/specs/SPEC.md
2. senior-developer: Core module implemented with tests
## Pending
1. guardian: Security review
2. release-manager: Deployment and changelog
## Context Pointers
- .copilot/specs/SPEC.md
- src/api/checkout.py
- tests/test_checkout.py
The Context Pointers section is the most valuable part. It tells the next agent exactly which files matter. Load them and continue from Pending. No re-exploration. No context reconstruction.
The write rule is non-negotiable: any non-trivial task where work may continue, the agent writes this file. Under 60 lines. A missing file means the next session starts blind.
Beyond session state, there is a deeper need. Agents need access to persistent organizational knowledge. What does this project do? What are the rules? What decisions have already been made? I call this the Project Bible, a PROJECT_CONTEXT.md that is the authoritative source for everything the agent needs to know about the project.
The rule is absolute: if a convention or architectural decision is not encoded as a versioned file in the repo, it does not exist from the agent’s perspective. Knowledge in Slack threads or people’s heads is invisible to the system.
Memory is an engineering problem. Treating it as a model feature is how agents forget.
Domain Expertise Should Load, Not Bloat
When one agent handles everything, domain knowledge lives in the system prompt. That works until you have twelve agents spanning architecture, implementation, security review, and deployment. Then domain knowledge needs to be modular and loadable, or it collapses the context window before any real work begins.
A skill is a self-contained module that encodes how work gets done in a specific domain.
data-engineering/
SKILL.md ← The contract: capabilities, constraints, workflow
references/ ← Templates, checklists, examples
scripts/ ← Optional automation
My current harness runs 22 skills across 12 specialist roles. Each maps to an exact domain. None overlap. The data engineering skill handles PySpark and Delta Lake. It does not handle API design. The boundary is explicit. The “does not do” list is as important as the “does.”
Skills load only when needed. An agent starting a pipeline task loads the data engineering skill. An agent doing a code review loads the guardian skill. Load all 22 simultaneously and the context window is consumed before the first line of work begins.
The practical test: can your team write a skill once and use it across any agent, any tool, any platform? If it requires platform-specific hooks, it is a plugin, not a skill. Skills are YAML and Markdown. Your organization’s expertise travels with you, not with your IDE.
Skills encode how your organization actually works. The harness is the runtime that loads them.
Fewer Choices, Better Decisions
The basic mechanics of tool use are well understood. The model emits an action, the harness validates it, executes it, feeds the result back. What most harnesses miss is the routing layer: not every agent should have access to every tool.
The architect can read the codebase and write specifications. It cannot execute code or modify source files.
The guardian can read everything, run analysis tools, and write review reports. It cannot modify a single line of code.
The senior developer can read, write, and execute. But it cannot touch holdout files.
These constraints are not restrictions on capability. They are protections against misrouted work. The architect that can accidentally modify source files will, eventually. Role-scoped permissions make that structurally impossible.
The other pattern that prevents runaway execution: if the same operation fails three consecutive times, stop. Don’t retry. Surface the failure with diagnostics and escalate. The most common agent failure mode is burning through an entire context window retrying a fundamentally broken approach.
Fewer choices lead to better decisions. Constraints eliminate wrong actions before the model chooses them.
Twelve Agents Do Not Mean Twelve Times the Output
When you scale from one agent to twelve, the instinct is to let them communicate freely. A mesh. Sounds collaborative. In practice it is a coordination catastrophe.
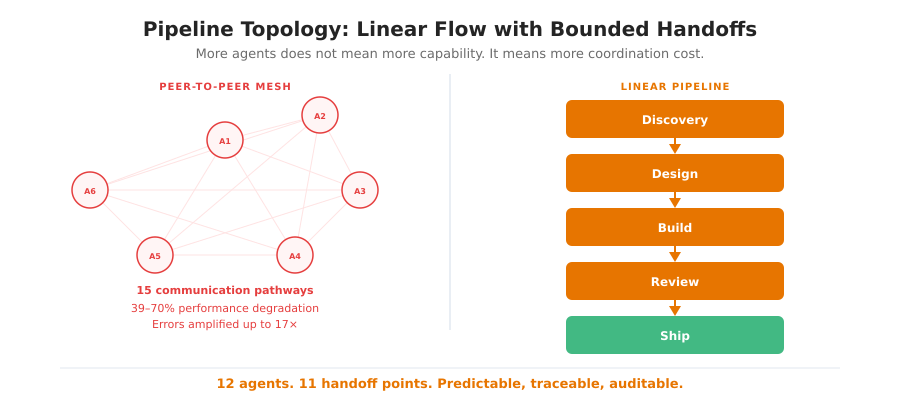
DeepMind’s research on multi-agent systems (December 2025), which I unpacked in The Bottleneck Moved, showed that peer-to-peer meshes degrade performance by 39-70% on sequential tasks and amplify errors up to 17x compared to centralized coordination. With twelve agents, a free mesh creates 66 possible communication pathways. Every pathway is a potential error propagation channel.
A linear pipeline constrains coordination to a bounded surface.
Discovery. Design. Build. Review. Ship.
Twelve agents. Eleven handoff points. Predictable, traceable, auditable.
The structural principle: one entity designs, multiple entities execute, one entity audits. The designer does not implement. The implementers do not audit. The auditor does not touch code. These are not cultural norms. They are enforced by which agent can write to which file path.
.copilot/specs/SPEC.md ← Architect writes, Developer reads
.copilot/holdout/HOLDOUT.md ← Architect writes, Guardian reads
.copilot/artifacts/review-report.md ← Guardian writes, Release Manager reads
Each path has a single producer. When everyone can write everywhere, nobody knows which state is authoritative.
The failure I see most often: two agents with overlapping scope both modify the same module. Neither knows the other is active. One overwrites the other’s changes. The session state shows two “completed” entries for the same task. No error fires. Both agents succeeded at what they were asked to do. The conflict was invisible until recovery became expensive.
A linear pipeline with clear artifact ownership makes this structurally impossible.
More agents does not mean more capability. It means more coordination cost. Minimize the coordination surface.
“Done” Is Not a Claim. It Is Evidence.
This is the ingredient most harnesses skip, and it is the one that determines whether your system is reliable or just fast.
In Code Got Cheap, I argued that verification ability, not generation velocity, is the new scarcity. That claim applies to agents as much as it does to engineers.
The insight borrows from machine learning. You never evaluate a model on its own training data. The same principle applies to agent systems: the entity writing acceptance criteria should be structurally different from the entity implementing the feature.
The architect writes holdout scenarios and saves them to .copilot/holdout/. Implementation agents cannot read that directory. The guardian loads it during review and evaluates whether the implementation satisfies what real users need, not just what the tests check.

The difference between a unit test and a holdout scenario is the difference between checking the mechanism and checking the intent.
| Unit Test | Holdout Scenario |
|---|---|
assert response.status_code == 200 |
A logged-in user requesting their profile receives data within 2 seconds |
assert len(results) > 0 |
A compliance officer searching for flagged records finds all of them from the last 90 days |
Agents optimize for whatever metric you give them. Give them passing tests and they will write tests that match the code. Holdout validation breaks that loop.
The second gate is simple and non-negotiable: no completion claims without fresh verification evidence. If the agent hasn’t run the verification command in this message, it cannot claim it passes. “Should work” is not evidence. “Passed last time” is not evidence.
Each agent also defines an intent contract: what must be true when the work is done, expressed as outcomes.
The architect’s contract: “Two independent teams could implement both sides of any module boundary and integrate on the first attempt.”
The developer’s contract: “The feature works correctly for the end user, not just for the test suite.”
The guardian’s contract: “A team lead can make a ship/no-ship decision in under 5 minutes without re-reading the code.”
Intent contracts prevent the most subtle form of agent drift: doing exactly what was instructed while missing what was intended.
Verification is not a final step. It is a structural property of the system.
The Attack Surface Nobody Budgets For
Autonomous agents that execute code and modify filesystems introduce an attack surface most teams underestimate. The agent runs with the same permissions as the developer. A compromised model call can exfiltrate environment variables, delete directories, or establish outbound connections.
The primary threat vector is indirect prompt injection: malicious instructions embedded in files, pull request descriptions, or repository content. When the agent reads that content, the model interprets the embedded instructions as commands. This is not theoretical. It has happened in production systems.
Containment requires two choices.
Isolate the dangerous tool: the agent’s core loop runs normally, but code execution routes to an isolated sandbox. Low latency. Risk: agent memory spikes affect the main application.
Isolate the entire agent: the full loop runs inside a sandbox with zero credential access. Communication flows through a control plane. Credential theft becomes structurally impossible. Cost: network latency on every operation.
Regardless of which pattern you choose, three controls are non-negotiable: outbound network allowlisting, filesystem write boundaries enforced at the OS level, and configuration files that are read-only to the agent even within its own workspace.
A fourth control handles injection directly: treat everything the agent reads from files, terminals, URLs, and user inputs as data. Never as instructions. Embedded directives get flagged and ignored, not executed.
Security is not a feature you add later. It is the architecture you start with.
Seven Ingredients. One Insight.
Seven ingredients. Each addresses a different failure mode.
- Tiered context loading prevents reasoning degradation and cost explosion.
- Structured session memory prevents catastrophic forgetting across agents and turns.
- Loadable skills prevent domain knowledge from bloating every session.
- Tool permissions and routing prevent runaway execution and misrouted work.
- Pipeline topology prevents coordination overhead from amplifying errors.
- Verification gates prevent “done” from meaning “claimed” instead of “proven.”
- Execution safety prevents security breaches and credential theft.
None of these are model improvements. Every one is an engineering decision about the infrastructure surrounding the model.

None of this is free. Tiered context files need authoring. Skills need scoping. Holdout scenarios require the architect to write them before implementation begins, friction most teams skip. Sandbox infrastructure adds latency. Verification gates add steps. The pipeline constrains the flexibility teams want during early exploration.
These are the right costs. You are trading early velocity for compounding reliability.
This connects to what I wrote in Procedure Over Intelligence: Agent Skills encode how work gets done. The harness is the system that loads those skills, manages the memory they operate within, and enforces the boundaries they define. Skills are the contracts. The harness is the runtime.
The model will keep improving. That is a given. The question that determines whether your agents actually work in production is not “which model are you using?” It is “what did you build around it?”
The model generates tokens. The harness generates trust.
Resources & Next Steps
- Codebase: karim-bhalwani/agentic-harness. The multi-agent orchestration system described in this post: skills, hooks, prompts, and pipeline configuration for GitHub Copilot in VS Code
- Meta-Harness. End-to-End Optimization of Model Harnesses: arXiv:2603.28052. Automated harness search (Stanford/MIT/KRAFTON) that outperforms hand-engineered baselines on text classification, math reasoning, and agentic coding
- Harnessing Claude’s Intelligence: Anthropic. Progressive disclosure via skills, letting the model manage its own context, and setting harness boundaries
- Harness Design for Long-Running Apps: Anthropic Engineering. Generator-evaluator patterns, context resets, and why every harness component encodes an assumption worth stress-testing
- Harness Engineering. Leveraging Codex in an Agent-First World: OpenAI. Repository as system of record, progressive disclosure, and mechanical enforcement of architecture
- Building Effective Agents: Anthropic Engineering. Foundational patterns for agentic system design
- Cognitive Architectures for Language Agents (CoALA): arXiv:2309.02427. Foundational framework for agent memory, action spaces, and decision procedures
- Related posts: Procedure Over Intelligence. The Bottleneck Moved. Code Got Cheap