Context Matters When Redacting Health Records for AI Analysis

When it comes to performing clinical research, evaluating insurance claims, or analyzing hundreds of pages of medical records, the biggest hurdle isn’t the data volume, it’s the privacy.
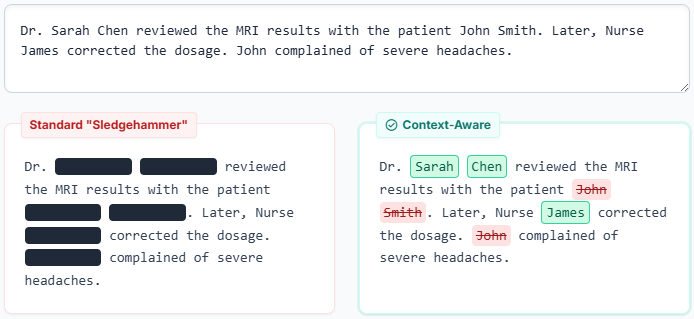
In workflows where humans must manually review clinical narratives, the goal is to leverage GenAI and LLMs to accelerate the process. However, to do this safely, we must de-identify health records (PHI/PII) first. The problem is that most tools use a “sledgehammer” approach: if a word looks like a name, redact it. In a clinical narrative, this leads to Over-Redaction, where critical professional context is lost.

Most redaction systems are built on NER (Named Entity Recognition) and deterministic patterns. They identify tokens that look like people, locations, or organizations, then apply masking rules. The underlying question is binary: is this span a PERSON entity or not?
That framing is insufficient for healthcare documentation. Patients and providers are both people, but they carry very different privacy and analytical implications. Patients require strict protection. Providers define workflows, responsibility, and escalation paths. A generic PERSON label collapses those roles into one category.
In this post, I’ll discuss building the Context-Aware Redactor, to solve this “Patient vs. Provider” dilemma for high-stakes manual review and AI-assisted analysis.
Overview
Context-Aware Redactor treats redaction as a semantic classification problem rather than a string-matching exercise. The goal is not to decide whether a token looks like a name, but whether it functions as patient data in context.
The system extends Microsoft Presidio and spaCy core capabilities, introducing a Two-pass orchestration pattern with layered distinction logic.

The first pass focuses on precision. It identifies patient information only when there are strong grammatical or contextual signals. Those findings populate a request-scoped cache.
The second pass improves recall. It uses the cached patient names to find additional mentions elsewhere in the document, while explicitly avoiding provider contexts.
This two-stage approach is critical. Precision-first detection establishes ground truth. Recall-focused matching builds coverage without increasing false positives. The result is redaction that is both safer and more useful.
Layers of Distinction
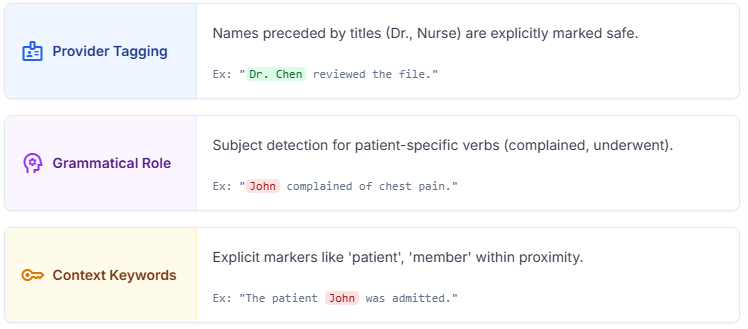
Context-aware redaction relies on multiple independent signals. No single heuristic is trusted on its own.
Layer 1: Healthcare Provider Tagging
Provider titles are detected before redaction logic runs. Names preceded by titles such as Dr, Physician, Nurse, or Cardiologist are marked as providers and excluded from patient redaction.
Layer 2: Grammatical Role Analysis
Clinical text follows predictable grammatical patterns. Using dependency parsing, the system identifies when a person is the subject of patient specific actions such as complained, reported, or underwent.
Layer 3: Contextual Keywords
Explicit markers such as patient, member, participant are strong signals. When a name appears near these keywords, it is treated as patient data.
These layers reinforce each other. Ambiguity in one signal is resolved by another. Edge cases are handled defensively, ensuring that while the patient’s identity is scrubbed, the clinical “who’s who” remains intact.
Data Handling
Clear data handling rules are essential for trust.
Patient data is always redacted. This includes names, dates of birth, contact information, health numbers, medical record identifiers, and financial identifiers tied to individuals.
Provider data is preserved when it appears in a professional context. Names, titles, departments, and institutional affiliations remain visible because they define decision pathways.
Clinical content is not altered. Diagnoses, procedures, medications, and care coordination details remain intact for review and analysis.
This separation aligns with how reviewers reason about documents. Privacy is protected without erasing the structure that gives the text meaning.
Technical Foundation: Extension, Not Invention
The system extends industry standards rather than building from scratch.
Microsoft Presidio provides the core framework. Presidio’s modular architecture allows custom recognizers while maintaining robust anonymization. The implementation extends Presidio’s PatternRecognizer and EntityRecognizer base classes for domain-specific detection logic.
spaCy supplies linguistic analysis. Specifically, custom pipeline components extend Presidio’s SpacyNlpEngine for clinical-specific role extraction.
This extension ensures:
- Single-pass NLP (Natural Language Processing): Text is parsed once, results are reused across recognizers
- Dependency parsing: Clinical relationships are extracted directly
- Custom attributes: Tokens are tagged with clinical roles at parse time
- Pipeline integration: Role extraction happens as a core NLP step, not post-hoc
The recognizers then consume these pre-computed annotations, making detection more efficient and accurate. All tuning is configuration-driven via a central patterns.yaml file. Provider titles, patient verbs, and contextual keywords are defined outside the code, allowing for controlled evolution as document styles vary across organizations.
Real-World Impact: Humans in the Loop
Claims Review teams use context-aware redaction to triage large volume document sets quickly. GenAI can generate summary highlights of unusual patterns or missing documentation, allowing reviewers to focus their time on judgment rather than identification.
Clinical Research teams work with sensitive internal datasets without risking accidental exposure. Patient privacy is preserved while institutional context crucial for understanding care pathways remains available.
Operational Intelligence teams analyze decision routes across departments. They can correlate outcomes with specific roles and approval chains that would otherwise be lost in a generic redaction sweep.
Security and Privacy
The system is designed with defensive defaults.
Redaction happens locally before documents reach any LLM or external service. Patient data is removed at the edge of the workflow, ensuring sensitive information never leaves the secure processing boundary.
Logs never contain personal data. Only aggregate metrics and timing information are recorded.
Each request uses an isolated cache. No patient identifiers persist beyond the scope of a single execution.
Inputs are validated early, and failures degrade safely. Errors do not expose content or partial outputs.
These controls support both on-premise deployments and controlled cloud environments.
Closing
Privacy and analytical utility are not mutually exclusive. They only conflict when redaction ignores semantic role.
For GenAI-assisted document review, preserving who made decisions is as important as protecting who received care. Context-aware redaction enables that balance by aligning privacy controls with how healthcare documents are actually used.
Resources & Next Steps
- GitHub Repository: Link to repo
- Full Architecture Documentation: TECH-ARCHITECTURE
- Interactive AI Knowledge Base: Explore & Chat with the Codebase