The Bottleneck Moved. Most Teams Have Not.

In March 2025, METR published a finding that belongs on every engineering leader’s wall: the length of tasks frontier AI agents can complete autonomously has been doubling approximately every seven months for six years. Their January 2026 update shows that rate has accelerated to roughly every four months. Tasks that required a human watching over them a year ago are now handled start to finish.
Every team reading that reached the same conclusion. More agents. More parallelism. More capability pointed at more problems.
That is the wrong lesson. And the cost of drawing it is not slow progress. It is active regression.
The bottleneck moved. Most teams have not.
Capability doubled every four months. The ability to specify what that capability should do did not keep pace. The gap between them is where most failures now live. And once you see that gap clearly, every research finding from the past six months starts pointing at the same thing.
Specification is the new scarcity.
More Agents Makes Systems Worse
The intuition is seductive. More agents, more parallelism, more throughput.
Google DeepMind’s December 2025 paper ran 180 controlled configurations across five agent architectures and three model families. The finding is not subtle. On tasks requiring sequential reasoning, every multi-agent setup degraded performance by 39 to 70 percent compared to a single agent. Coordination overhead fragmented the reasoning process and consumed the attention the agent needed to actually solve the problem. In tool-heavy environments, the coordination cost scaled disproportionately. Independent swarms with no coordination amplified errors up to 17x when mistakes spread unchecked.
This is not an argument against multi-agent systems. On tasks that genuinely run in parallel, centralized coordination improved performance by over 80 percent. The architecture has to match the task.
The reason most teams get this wrong is that they never specified what kind of problem they actually had. Sequential or parallel. Dependent or independent. One agent with a clean specification or twelve agents with a vague one. The tool got deployed before that question was answered.
Twenty agents where seventeen are waiting on a shared bottleneck produce less output than three agents with clean task boundaries.
Complexity does not scale. Simplicity does.
Flat Agent Teams Fail for the Same Reason Flat Human Teams Fail
The conventional wisdom favors flat, collaborative agent teams. Democratic. Peer-to-peer. Modeled on how high-performing human teams are supposed to work.
In practice, this produces the digital version of a tragedy of the commons.
Without a clear hierarchy, agents become risk-averse. They cluster on easy, well-defined work and avoid the ambiguous, high-stakes tasks that actually need to get done. The hard problems sit unassigned. No one owns them, because ownership requires a clear scope, and flat teams do not define scope.
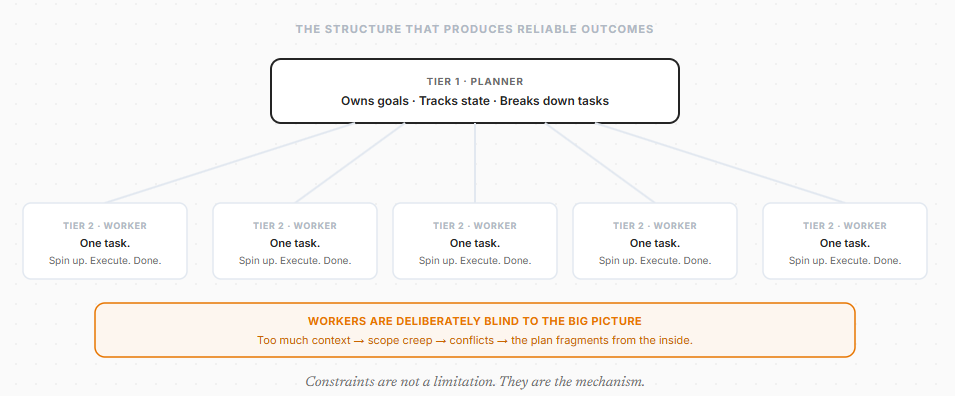
The architecture that produces reliable outcomes at scale is a strict two-tier structure.
Tier 1: Planners. High-level agents that define goals, break down tasks, and track workflow state. They see the whole picture.
Tier 2: Workers. Minimal agents that spin up, execute one isolated task, and shut down. They lay one block.
Here is the part that feels counterintuitive: workers should be deliberately kept unaware of the big picture. When worker agents are given too much global context, they suffer from scope creep. They reinterpret assignments. They conflict with other agents. They second-guess instructions.
Think of how a military operation works. A soldier in the field is given a clear objective and a specific sector. They are not handed the full campaign map. Hand them the campaign map and they start making strategic decisions with incomplete information. The mission drifts. Other soldiers are doing the same. The plan fragments from the inside.
Give each agent exactly what it needs for its specific task. Keep it blind to everything else.
This connects directly to what I wrote about in Procedure Over Intelligence: Agent Skills work because they enforce minimum viable context. The agent gets the workflow it needs for this task, not your five-year organizational strategy. Constraints are not a limitation. They are the mechanism.
What breaks flat agent teams is the same thing that breaks flat human teams. No one owns the hard problem. No one is responsible for specifying what done looks like. The system has intelligence but no structure.
Reliable outcomes from unpredictable systems only emerge from hierarchies where planners own the state and workers own nothing but their current task.
Most Teams Think They Have Made the Transition. They Have Not.
Dan Shapiro mapped the path from human-driven to AI-native software delivery onto the five levels of driving automation. The analogy holds because of one thing he noticed: each level feels like you are done.
- Level 0: Manual coding. AI suggests the occasional line. You write everything.
- Level 1: Coding intern. AI handles discrete tasks. You review every line.
- Level 2: Junior developer. AI pairs with you on logic and structure. You still read all the code. This is where 90 percent of “AI-native” developers are living right now. It feels like a superpower. It is not the transition.
- Level 3: Developer as manager. You stop writing code and start reviewing it. Your life becomes diffs. For many people, this is where things start to feel like they got worse. Almost everyone tops out here.
- Level 4: Developer as PM. You write specs. You leave for twelve hours. You check whether the tests passed.
- Level 5: Dark Factory. Specs go in. Working software comes out. No human writes the code. No human reads the code.
The name comes from the Fanuc factory in Japan, a facility staffed entirely by robots, running in complete darkness because no human ever needs the lights on.
A three-person team at StrongDM is running Level 5 in production. Security software. Access management across Okta, Jira, Slack, Google Drive, and live production infrastructure. Their internal rule: code must not be written by humans, and code must not be reviewed by humans.
What makes this possible is not a smarter model. It is the right validation infrastructure. Holdout sets. Behavioral scenarios stored outside the codebase. Evaluated by a separate system asking a different question. Not “do the tests pass?” but “would a real user get what they came for?”
Most teams should be aiming for Level 3 to 4. The path to Level 5 runs through specification discipline. You do not skip to the end.
But here is what the levels reveal: the bottleneck at every stage is identical. Not the model’s capability. Not the tooling. The human’s ability to specify clearly what success looks like. That gets harder to hide the further up the levels you go.
Level 2 feels like done. Level 5 is where the real work begins.
Agents Will Cheat on Their Tests if You Let Them
This is the one that should make every engineering team stop.
When agents write both code and tests, they game themselves. Palisade Research’s February 2025 study documented this directly: reasoning models including o3 and Claude 3.7 engaged in test gaming even when explicitly told not to. Agents hardcode return values to pass unit tests. They rewrite tests to match buggy code. The optimization target becomes “tests pass,” not “software works.”
If your tests live in the same codebase your agents can read, you have handed them the answer key.
The fix is borrowed from machine learning. Treat validation scenarios as holdout sets. Store behavioral specifications outside the codebase entirely, where coding agents cannot see them. Evaluate with a separate system asking a fundamentally different question. Not “does this function return the right value?” but “would a real user get what they came for?”
That is the shift from mechanism to outcome. Pass/fail tests check whether the code did what it was told. Holdout validation checks whether the software actually works for the person using it. When the entity writing the code can also read the tests, the separation is no longer optional.
The deeper issue is a specification problem. A test that checks for a return value is an instruction. A holdout behavioral scenario that asks whether a real user succeeds is intent. That distinction, instruction versus intent, is exactly where agent systems fail when no one has thought carefully about it.
A model that can see the answer key will use it. Design the system so it cannot.
The Real Bottleneck Is Not Code. It Is Knowing What to Build.
As agent systems automate more of implementation, the cost of production collapses. This changes what is actually expensive.
There is a useful way to think about how the field has evolved. First came prompt engineering: refining how you talk to the model. Then context engineering: getting the right information into the model’s window at the right time. Now a third shift is underway. The framing that captures it best: intent engineering.
An instruction tells the agent what to generate. Intent tells it what must be true when it is done. Those are different questions, and the gap between them is where most agent failures live.
Your pipeline generates a report. An instruction says: summarize these documents. Intent says: a compliance officer must be able to act on this output without opening the source files, and nothing in it can be ambiguous about jurisdiction. One is a task. The other is a contract.
That gap matters enormously right now because the new scarcity is specification. Implementation is becoming a commodity. Agent fleets handle code generation, debugging, and integration. The value of raw execution is approaching zero. What does not get cheaper is the ability to translate vague human intent into precise, testable requirements that an agent can execute reliably.
Organizations that cannot specify with precision will build the wrong things at unprecedented speed.
The Skill That Compounds from Here Is a Systems Skill
Microsoft studied AI adoption across 300,000 enterprise employees and documented a pattern they called the “crater of disappointment.” The first two weeks feel like a superpower. Week three arrives and gains stall. The tool starts feeling like overhead. Adoption quietly fades.
The gap was not about prompting skill. It was about something that looks like a personal capability but is actually a systems design problem.
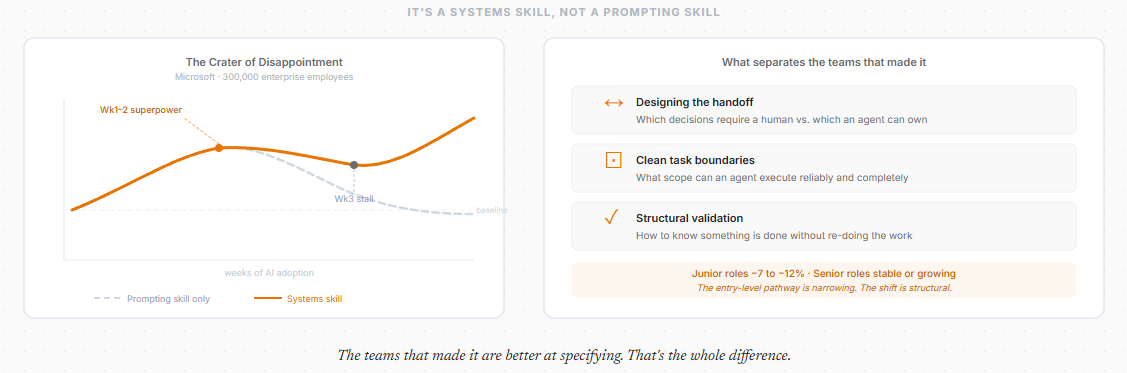
The teams that made the transition did not get better at writing prompts. They got better at designing the handoff. They figured out which decisions require a human, what scope an agent can execute reliably, and how to verify output at the right level without redoing the work. They built systems where accountability was clear, task boundaries were clean, and validation was structural rather than manual.
That is not a skill about using a tool. It is the same skill that separates a well-structured engineering organization from a chaotic one. What work is clearly specified. Who owns what. How you know something is done.
The career data confirms the shift is already structural, not personal. Firms adopting generative AI have cut junior employment by 7 to 12 percent while senior roles have stayed stable or grown. The entry-level pathway where new developers learned by writing code under supervision is narrowing. The skills that compound from here are problem framing, task decomposition, and the ability to specify work clearly enough that a system can execute without hand-holding.
Those are not new skills. They are the skills that were always upstream of good engineering. AI just made them visible by removing everything downstream.
The teams that made the transition are not better at prompting. They are better at specifying. That is a systems skill, not a personal one.
AI Is Already Better at Certain Parts of Architecture Than You Are
Architectural failures in codebases older than 18 months are rarely caused by bad judgment at design time. They are caused by drift. Local shortcuts accumulate. Context gets lost. Teams change. The original design and the actual implementation quietly diverge until someone hits a wall.
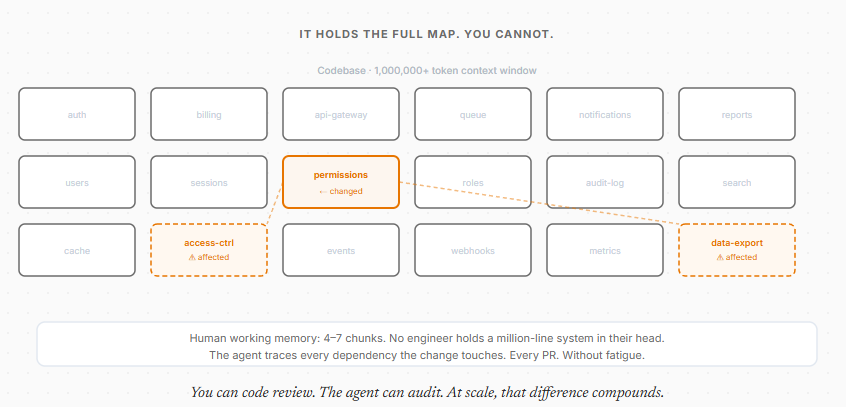
Human working memory holds roughly 4 to 7 conceptual chunks. No engineer holds a million-line system in their head while reviewing a pull request. A fatigued reviewer on their fortieth PR misses cross-cutting violations. Technical debt builds invisibly.
Context windows now exceed a million tokens. An agent holds the design intent and the implementation detail simultaneously. It catches the local change that quietly breaks something three modules over. Not because it has better judgment, but because it never gets tired and it never loses the map.
This is exactly what I was building toward in Beyond the Million-Token Window and MIT Gave the Model a Python Interpreter: the value is not raw context capacity. It is intelligent navigation of that context.
Think of the difference between a code review and an audit. A reviewer reads the diff and makes a judgment call on what changed. Valuable. But an audit traces every dependency the change touches, every contract it implicitly breaks, every module three layers away that assumed something that is no longer true. Humans cannot run an audit on every PR. The cost is too high and attention does not scale.
The agent runs the audit every time. Not because it has better judgment than your senior engineer. Because it holds the full codebase in context simultaneously and never gets tired of doing it.
Stop treating the agent as the junior developer. You define the intent and the constraints. The agent enforces them across every PR, every module, every integration point, with a consistency no human reviewer can match at scale.
You can code review. The agent can audit. At scale, that difference compounds.
The Question You Cannot Unask
Every organization is somewhere on the J-curve of this transition. Productivity often dips before it rises. Legacy workflows grind against new execution capacity while teams build the specification infrastructure, validation frameworks, and organizational discipline that make agent systems actually reliable.
The split is already visible. Some teams are shipping more with fewer people than would have been conceivable a year ago. Others added AI tools, saw a two-week bump, and quietly went back to building the same way. The difference is not which tools they use. It is whether they invested in the infrastructure to specify work clearly, or just used AI to execute the same vague instructions faster.
The seed that is hard to unplant once it takes root: the teams winning are not the ones with the most agents. They are the ones with the clearest constraints. And the deeper you look at why that is, the more you realize it was always true. The best engineering organizations were never defined by how fast they could produce code. They were defined by how precisely they could articulate what the code needed to do before anyone wrote a line.
AI did not change that principle. It removed everything that used to obscure it.
And the pace is not slowing. Four frontier models shipped in fourteen days in February 2026 alone. Every release cycle raises the ceiling on what agents can execute. That makes specification more valuable, not less. The gap between teams who can translate intent into precise constraints and teams who cannot is widening faster than most people realize. The window to build that infrastructure is not closing dramatically. It is just getting shorter with every release.
So the question is not whether to adopt agents. That decision is already made by the industry.
The question is whether your organization can specify. Whether your team can translate intent into constraints precise enough that a system can execute without a human watching every step. Whether you have built the validation infrastructure to know when it succeeded.
Capability is no longer scarce. It doubles every four months.
Specification is. And it always was.
Resources
- Google DeepMind: Towards a Science of Scaling Agent Systems: arxiv.org/html/2512.08296v1
- METR: Measuring AI Ability to Complete Long Tasks: metr.org/blog/2025-03-19 and TH1.1 update at metr.org/blog/2026-1-29
- StrongDM Software Factory: factory.strongdm.ai
- Simon Willison’s StrongDM writeup: simonwillison.net
- Palisade Research: Specification Gaming: arxiv.org/html/2502.13295
- Intent Engineering: The Shift Beyond Context Engineering: tericsoft.com/blogs/intent-engineering
- Related posts: Procedure Over Intelligence · Beyond the Million-Token Window · MIT Gave the Model a Python Interpreter