MIT Gave the Model a Python Interpreter. The Results Are Hard to Ignore.

In my last post, I argued that context capacity and context intelligence are not the same thing. A million-token window doesn’t solve multi-hop reasoning. It just makes the failure modes more expensive. The fix was architectural: hierarchical navigation, scratchpad routing, cache-augmented generation. Build a system that reads documents the way a human expert does.
That framework works. But it assumes the decomposition strategy is designed in advance. You define the tree structure. You write the routing logic. You decide how chunks relate to each other.
MIT’s Recursive Language Models (RLMs), published December 31st 2025 by Alex Zhang and Omar Khattab, invert that assumption. Let the model decide how to decompose the problem at inference time. That shift is more significant than it first appears.
What RLMs Actually Change
A standard LLM call looks like this:
llm(query + context)
The model passively consumes everything and produces an answer. The failure modes from my last post all stem from this: attention degrades in the middle, multi-hop chains get lost, the Key (K) and Value (V) cache fills with noise.
An RLM call behaves differently:
rlm(query, context)
Here, context is not input. It is a variable inside a controlled execution environment, implemented as a Python REPL (Read-Eval-Print Loop). The root model sees only the user’s question and the knowledge that a large context object exists somewhere in memory. It must write code to interact with that object.
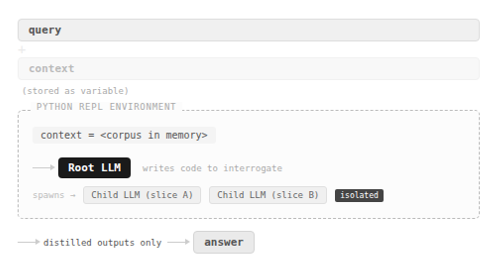
Four behaviors emerge naturally from this constraint.
Peeking. Before committing to any strategy, the model grabs a small slice of the corpus to understand its structure. Think of a developer running head 100 on an unfamiliar dataset before writing a query against it.
Grepping. Rather than reading everything, the model searches programmatically for anchors like section headers, defined terms, or entity IDs. It narrows the search space before zooming in.
Partition and Map. When grepping isn’t enough because the question requires semantic reasoning, the model chunks the corpus programmatically and dispatches recursive sub-queries to child LLMs over each slice. Each child operates in its own isolated context and returns only its conclusion. The parent’s context stays clean.
Structured Synthesis. For questions requiring synthesis across many fragments, the model builds up intermediate results in a structured way before forming the final answer.
The parent-child isolation is the key mechanism here. Whatever noise a child LLM encounters during its work never surfaces to the parent. The parent sees only distilled outputs. This is why context rot doesn’t compound across the chain, and why performance holds at token counts where flat ingestion completely collapses.
How This Compares to Hierarchical Navigation
Both approaches address the same underlying failure. Flat ingestion doesn’t scale reasoning. But they differ in where decomposition happens.
Hierarchical navigation is pre-designed. The tree structure, routing heuristics, and chunk boundaries are all decided at design time. The system is predictable and auditable. You can trace exactly which routing decision led to which retrieved content. That matters a lot in regulated environments or anywhere you need to explain the system’s behavior.
RLMs are adaptive. The model invents its own decomposition strategy per query, per document, at inference time. You don’t need to anticipate the document structure or the query type in advance.
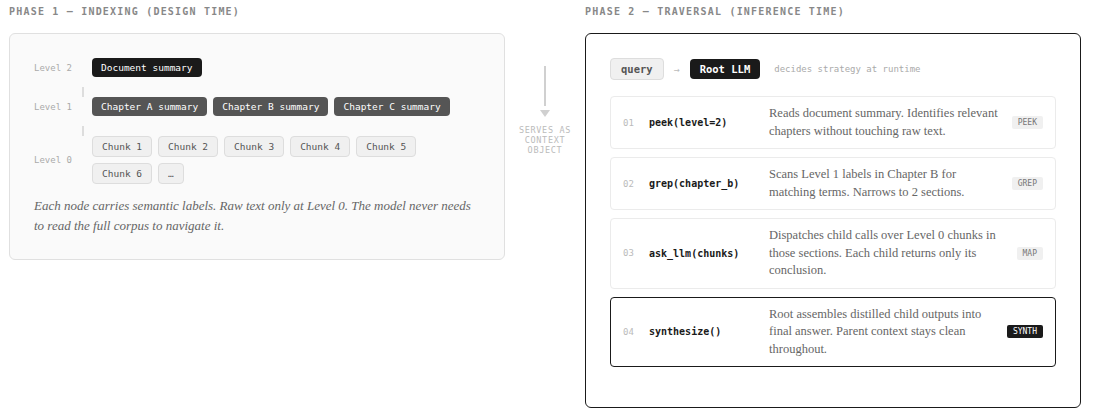
These two approaches are not mutually exclusive, and the combination is worth building toward deliberately. A precomputed RAPTOR tree can serve as the RLM’s context object. In that setup, the model isn’t navigating raw text. It’s navigating a hierarchy of labeled summaries and chunk metadata that a prior indexing step produced. The RLM then decides at inference time which branches to descend, which sections to grep, and when to dispatch child calls, all over a structure that has already been organized for it.
This matters in practice for two reasons. First, the RAPTOR tree dramatically shrinks the search space the RLM has to explore programmatically, which reduces both latency and token cost per query. The model can peek at a Level 2 summary rather than peek at raw text. Second, the tree preserves the auditability of hierarchical navigation. You can trace which branch the RLM entered and verify the routing was reasonable, even though the model chose the path at runtime rather than a designer choosing it at build time.
The most robust production systems will likely run this way: a pre-architected structure that the model can adaptively traverse.
The Performance Case Is Real, Within a Specific Problem Class
The benchmark results are strong, but they are best understood in context before generalizing.
On OOLONG, a benchmark requiring semantic mapping across thousands of entries, RLM(GPT-5-mini) outperforms a flat GPT-5 call by over 34 points at 132k tokens — roughly a 114% increase in correct answers, at comparable API cost. Important caveat: OOLONG is a narrow benchmark. The task is a well-defined query over a large, structurally uniform corpus. That is precisely what RLMs are built for. The gains are real. They should not be read as a general claim across all document types.
On BrowseComp-Plus at 1000 documents (roughly 10M tokens), RLM(GPT-5) is the only method that maintains near-perfect performance. Flat ingestion truncates and fails. BM25 retrieval degrades on multi-hop queries. RLM works because no individual call ever sees the full corpus, and cost scales sublinearly with corpus size rather than linearly.
The framework is also model-agnostic. It works across GPT-5, GPT-5-mini, and smaller open models. This is an inference harness, not a capability baked into specific weights. Smaller, cheaper models can outperform larger ones on the right class of problems.
From Benchmark to Production
The MIT paper is a research contribution, not a production deployment guide. The benchmark numbers are valid and the architecture is sound. But there are gaps between “works in a benchmark” and “safe to ship to users” that the paper doesn’t address. I found these through hands-on implementation.
Six controls worth adding before you deploy:

-
Code scanning before execution. The REPL executes model-generated code. User documents can influence that code via prompt injection. A pre-execution scan should block dangerous imports, dynamic execution primitives (
eval,exec), introspection escapes, and write-mode file operations. Reject silently — don’t hand attackers a roadmap. -
Allowlist over blocklist. Blocklists assume you’ve anticipated every attack vector. Instead, expose only the ~23 builtins a reasoning task actually needs. The rest of the standard library simply doesn’t exist in the namespace.
-
OS-level resource limits. An LLM can generate an infinite loop or a memory bomb. Hard wall-clock timeouts and memory caps need to be enforced by process isolation, not by application code inside the sandbox. A compromised interpreter cannot reliably police itself.
-
Process isolation with a proxy pattern. Running each REPL step in a separate process is the cleanest security posture, but recursive LLM callbacks break naive process isolation. The fix is a queue-based proxy: the child sends requests through a queue, the parent handles the API call, results flow back the same way. Memory isolation stays intact.
-
Sub-query cost ceiling. A single RLM call can spawn many child LLM calls. Without a hard cap per root call and a rate limiter on dispatch, one adversarial query can exhaust your shared API quota.
-
Intermediate output truncation. Each REPL step’s output feeds back into the model’s context. Large early outputs compound and crowd out reasoning. Cap per-step output and prompt the model to expect truncation.
Where RLMs Fit
RLMs are not a replacement for the architectural thinking from my last post. They are an inference harness that adds dynamic decomposition on top of it.
Hierarchical navigation gives you predictable routing, auditable decision paths, and stable performance envelopes. RLMs give you adaptive traversal, query-specific decomposition, and efficient scaling to token counts that flat ingestion simply cannot handle. In high-variance document environments the latter is powerful. In regulated environments the former is stabilizing. The strongest production systems will combine both, with a pre-indexed RAPTOR structure serving as the object the RLM reasons over.
The benchmark results are real within the problem class they test. The architecture is elegant. The security layer, cost controls, and hybrid design are your responsibility to add before you ship.
The six controls above are each independently worth implementing. Together they give you a production posture for a genuinely useful capability. And placing an RLM over a precomputed hierarchical index is the architecture I’d build toward: you get the predictability of structured retrieval and the adaptiveness of runtime decomposition without trading one for the other.
Resources
- MIT RLM Paper: arxiv.org/abs/2512.24601v1
- RLM implementation: github.com/alexzhang13/rlm